Boost your business with our strategic consulting services, optimizing operations, enhancing efficiency, and unlocking growth opportunities for unparalleled results.
Elevate your digital presence by tapping into our service, driving online excellence, user engagement, and scalable solutions for a competitive edge in the digital landscape.
Transform your business with AI, Blockchain, and Machine Learning expertise, pioneering cutting-edge solutions that drive efficiency, security, and unparalleled insights.
Empower your decision-making process with our Business Intelligence & Reporting solutions, unlocking actionable insights, optimizing performance, and strategic success.
Get competetive advantage with our Bespoke Software Solutions, designed to amplify business efficiency, and provide a scalable foundation for growth
Technology Areas
Diverse Technology Areas, where expertise meets custom solutions, ensuring your business stays at the forefront of technological advancement.
Integrated Business Solutions
Efficiently integrate and consolidate finance, human resources, sales, marketing, and inventory management. Improve customer interactions, automate workflows, and enhance overall business agility through CRM, BPM, and SAAS solutions.
Digital & Big Data
Integrate digital aspects like online presence, digital marketing, e-commerce, cybersecurity, and data analytics. Efficiently manage structured and unstructured data with advanced analytics to extract valuable insights for strategic decision-making.
Infrastructure
Enhance software development cycles by streamlining testing for quality, reliability, and performance. Integrate and manage core IT elements such as networks, servers, storage, and cloud services to improve operational efficiency and scalability.
AI & RPA Solutions
Integrate advanced AI technologies like machine learning, natural language processing, and computer vision for intelligent decision-making and business automation. Use algorithms to analyze data, identify patterns, and make data-driven decisions.
Certified Tech Partner
As a company holding ISO 27001, ISO 9001, and SAP Partner certificates, we guarantee the highest standards in security, quality, and innovation to drive your success forward.
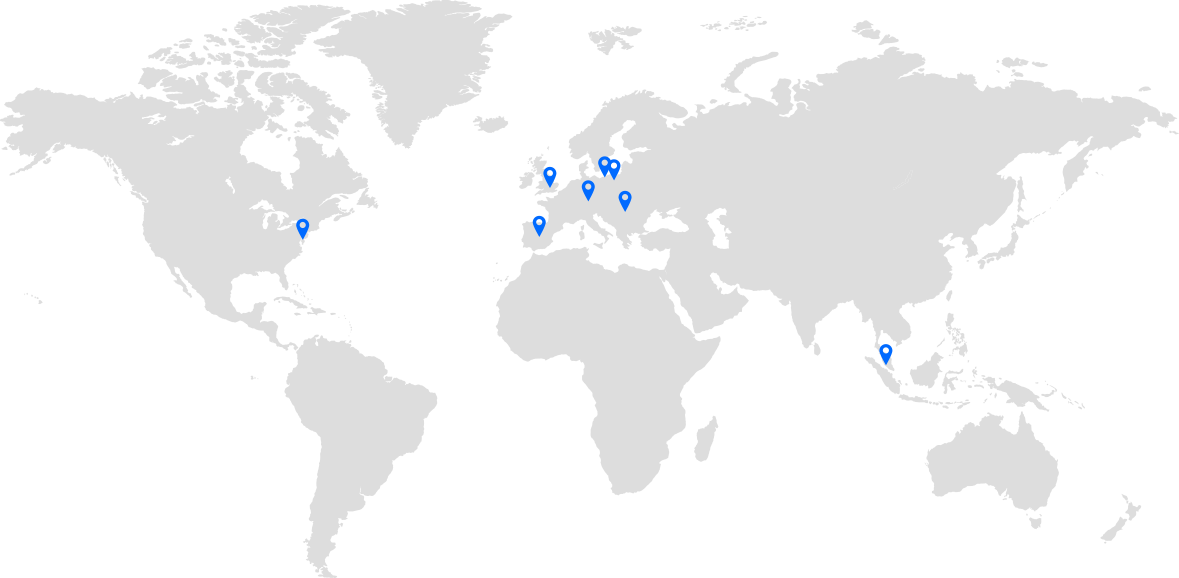
Our locations
With 10 strategically located offices worldwide, we adapt to your needs across time zones, ensuring constant support and accessibility.
New York
London
Madrid
Berlin
Kuala Lumpur
Budapest
Dover
Baar (Zug)
Słupsk
Gdańsk
Seargin In Numbers
0
Centers Of Excellence
0+
International Clients
0+
Professionals Onboard
0
Locations Worldwide
Trustworthy Tech Partner
Delivering value instead of simply completing project milestones is our approach at Seargin. We help companies transform their production lines and implement cutting-edge technology solutions into various business areas, making them compliant with Industry 4.0 standards.
Expertise
With over a decade of experience in data analytics and business intelligence, our seasoned professionals bring a profound understanding of industry best practices and the latest trends.
Custom Solutions
Customizing BI and reporting solutions to meet unique business needs, our team collaborates closely with you to align solutions with organizational goals. This approach provides essential insights for driving growth and success.
Advanced Technology
In our specialized R&D lab, we use cutting-edge tools to extract, transform, and visualize data. Proficient in various industry-leading technologies, our team ensures the selection of the most suitable solution for your business.
Trusted Team
With 50+ years of team experience in machine vision systems, industrial testers, and optical measurement solutions, rely on our trusted team as steadfast partners dedicated to your success.
Industry-Focused
Building cross-industry systems in healthcare, space, aviation, heavy industry, fintech, and beyond. Our specialized solutions position your business at the forefront of innovation and market leadership.
SAP & ServiceNow Partner
As trusted partners of SAP and ServiceNow, we focus on delivering value to clients, ensuring efficient business operations with up-to-date technological solutions.
Ready to elevate your business? Let’s start the conversation.